银河国际(GALAXY) 可重构数据流三十年:下一代计较平台之争

智东西
作家 | 程茜
剪辑 | 漠影
历经484天,大众AI产业翘首以盼的DeepSeek-V4厚爱发布、全面开源,其同步甩出的一份硬核本事答复,为算力时间的演进写下全新注脚。
它以系统级创新,将KV Cache限制膨大至百万级高下文;系统性压缩机制的引入,既裁汰存储与计较的巨大支出,也将计较活水线的深度与复杂度推向新高度,这每一处本事突破,都是对算力发展极限的叩问。
再将时刻拨回2025年末,还有一笔纵情成例的来回横空出世:英伟达以200亿好意思元天价拿下AI推理芯片独角兽Groq LPU推理本事的非独家授权,并将中枢团队纳入麾下。
DeepSeek-V4的本事演进,为数据流架构开释极限性能提供了适配场景;Groq 被英伟达收编后也同样押注的是数据流架构地方,这一产业新变量果决踏进大众AI产业中枢舞台,成为撬动算力革新波浪的弊端力量。
算力革新的急流奔涌上前,巨头的每一次布局,都装潢着行业迭代的风向。回望计较机本事的演进,每一次划时间的本事革新,骨子上都是一场对算力平台的豪赌,本事阶梯的采选常常决定了改日数十年的产业方法。
在PC与互联网的时间,英特尔(Intel)凭借x86架构的皆备性能总揽了算力疆域,并在此基础上构筑了难以撼动的软件生态帝国。然而,跟着HPC与AI波浪的到来,本事范式悄然切换。英伟达(NVIDIA)以CUDA生态配合TensorCore架构,较x86架构杀青了十倍的性能跃迁,建造了其新一代算力霸主的地位,助其登顶大众市值之巅,完成了从图形处理器到AI引擎桂冠的加冕。
因此,英伟达创举东说念主、CEO黄仁勋比任何东说念主都阐明,算力平台的更替从不温煦脉脉。夙昔英特尔在x86生态的祥和乡中千里睡,未能意象并行计较的波浪;如今英伟达坐拥CUDA帝国,刚直面一个更骄气的现实——当Transformer架构的算力需求每两年暴涨750倍,当单卡算力靠近物理极限,谁会成为新一代的算力平台?
十倍级的代际跃迁常常出身于架构的颠覆而非工艺的改造。在GTC 2026大会上,英伟达厚爱推出Groq 3 LPX机架级推理平台,黄仁勋称,Groq 3 LPX平台与Vera Rubin NVL72结合使用的夹杂架构,可杀青GPU强盛算力与LPU极致带宽的好意思满互补。这马上激勉行业关注。
纵不雅产业界,除了英伟达这个GPU霸主,正在给我方找一条“非GPU”的退路,此前英特尔被传以16亿好意思元价钱收购SambaNova,后转向深度相助。巨头们的烦燥已写在脸上。
而在国内,大额融资、订单的橄榄枝纷纷抛向鲲云科技等企业。
这些看似散布的热门,其实指向团结个本事原点——可重构数据流架构。
水滴石穿,新本事的演进、熟谙、落地也非一旦一夕之功。本事的起头不在GPU架构性能瓶颈逐渐明确确当下、亦不在GPU挑战CPU大众算力霸主的时间;它的起头在更早之前,在英伟达还未确立之时,在阿谁制程工艺快速迭代、CPU仍然总揽算力平台的时间,从几个学者的敬爱到学术社区的建立,从一代代实验室本事的传承到产业化的星火燎原,于今已过了三十多年。
让咱们把时钟拨回35年前,从牛津大学的一间会议室提及。
一、帝国理工学院的一间实验室,可重构数据流架构火种出身(1991-2000)
1991年,牛津大学的一间会议室内,陆永青博士谋略了一场计较机体系架构的研讨会,一种新的架构念念路运行被商讨:改变硬件来适配软件应用。
传统架构依赖教唆集体系进行计较管理,教唆间通过妥洽的存储地址空间进行配合,形成数据读写与计较的串行关系,影响计较效能擢升。
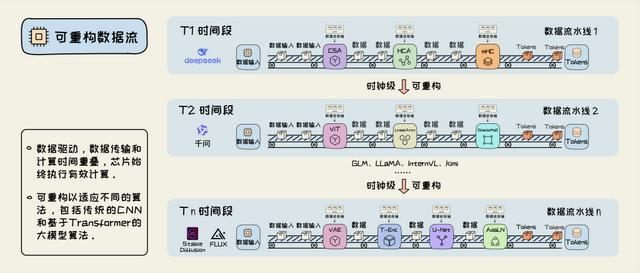
若是在架构诡计中将扫数教唆集移除,依靠深度活水线与数据流动次序肆意计较,如下图所示,表面上不存在数据读写带来的计较逍遥,不错发达物理极限性能。与此同期,在运行时重构计较电路,则不错治理计较通用性。
陆永青与其导师Ian Page找到了新的旅途,其推出的Occam高层编译秩序成为可重构数据流架构历史上初度给出的系统性工程化决策,在此次牛津大学研讨会上发表,成为自后Handel-C编译器的基础:用C谈话作念硬件并应用现场可编程本事,去兼顾极致性能与架构通用性。
此次研讨会,自后成为欧洲最大的可重构计较顶会FPL(现场可编程逻辑),连同陆永青创立的亚洲顶会FPT、其行为创刊主编创立的ACM TRETS,在尔后的数十年间,成为这个新本事阶梯的主阵脚。
不同于英特尔、英伟达所主导的固定硬件架构,改变软件适配不同应用,新出身的本事专注于完全相悖的地方:改变硬件适配不同应用。类比到汽车制造行业,就相等于工场大要改变活水线成立,从而针对不同车型打造有利的活水线,并通过传送带替代东说念主工搬运来治理数据搬运的时刻销耗,这种架构念念路频繁能带来10倍致使百倍的性能擢升。
1991年FPL海报(图源:FPL会议官网)
9月6日,会议扫尾,从此始创了一个全新的计较架构,等于如今可重构数据流架构的雏形,奠定了该本事改日的中枢发展地方。行为创举东说念主的陆永青也成为推动这一鸿沟发展的要津前驱东说念主物。
1995年,他从牛津大学转职帝国理工学院,确立定制计较实验室。行为可重构数据流本事的起源实验室,Groq、SambaNova、鲲云科技这些国表里有名创企真的立、演进,都与这家实验室有着千丝万缕的考虑。
本事的终极命题在于更好的落地应用。定制计较实验室出身初期对准的等于可重构数据流架构的两大中枢挑战:
• 数据流,面向特定应用场景杀青靠近物理极限的计较性能;
• 可重构,在千般化场景的定制化架构间杀青机动切换与通用适配。
自后Occam编译本事被分拆,确立了Celoxica,其Handel-C器用链部分被欧洲EDA巨头Mentor Graphics收购,而这家巨头等于如今大名鼎鼎的西门子EDA。
Celoxica的出身,初度将可重构数据流架构从表面构想淬真金不怕火为可供产业使用的算力决策。陆永青与德国粹者Markus Weinhardt所奠定的活水线矢量化秩序,也借此完成了从学术创意象工业基座的窜改,为行将到来的本事波浪埋下了决定性伏笔。
二、大欧好意思两岸火种交织,三代学者勤快啃下产业化鬈曲(2000-2016)
与此同期,大欧好意思此岸的斯坦福大学,亦点火了可重构数据流架构的筹议火种。
同为各自本事阶梯的奠基学者,陆永青与Flynn为多年一又友。Flynn解说诚然一直寄望于教唆集架构筹议,但他在Bell Labs使命的学生Oskar Mencer却对硬件数据流架构情有独钟,由他主导激动的StReAm,恰是面向自妥当计较诡计的典型数据流架构。
在奥地利FPL会议上,陆永青与Mencer相识,大欧好意思两岸的筹议星火厚爱交织,其后Mencer加入帝国理工任教职东说念主员,他们协力推动数据流电路的极致优化,通过将活水线中扫数软件移出,让硬件活水线赢得靠近物理极限的性能,杀青每个计较单位每个时钟周期都进行有用计较。

陆永青(左一)、Oskar Mencer(左二)获帝国理工学院超卓筹议奖(图源:帝国理工学院官网)
跟着筹议不息深入,可重构数据流架构与产业界的结合日益深厚,金融、医疗、石油勘测都成为这一本事旅途发达作用的场景。2003年,雪弗龙石油的油田勘测使命受算力瓶颈制约,Mencer打造了高性能加快计较平台,杀青了油田钻井效能的百倍擢升。
这之后,Mencer主导确立的Maxeler Technologies将上述研发后果产业化,自后他牢固专注于Maxeler的管理,逐渐淡出定制计较实验室。
Maxeler的数据流计较系统客户可谓大名鼎鼎,包含金融鸿沟的JP Morgan、Citibank,动力鸿沟的雪弗龙、ENI,还有英国Daresbury、德国Jülich等国度级超算中心。Maxeler与这些客户的相助证明,可重构数据流架构还是成为企业要津业务的刚需算力载体。
Mencer之后,海表里学者勇往直前。
陆永青解说创办的帝国理工定制计较实验室成为北好意思、欧洲、亚洲学术商讨与一样的交织点。Michael Flynn之后多位教唆集本事体系学者到定制计较实验室一样访学,其中就包括斯坦福大学的Kunle Olukotun解说。多年后,Groq收购了Mencer创办的Maxeler Technologies,而Groq恰是那时Olukotun创立的SambaNova在好意思国最大的竞争敌手,亦是这种大众本事一样下的势必。
随后,协助陆永青管理实验室的,同样是一位香港学者:本硕博均毕业于香港汉文大学的蔡权雄。他在定制计较实验室主导了CUBE与Axel集群两大符号性名堂,为可重构计较的限制化考据打下了弊端工程基础。
其中,CUBE将64颗FPGA在一个超大型印刷电路板上用Torus互团结构构成更大计较节点,谷歌TPU团队用2D Torus将TPU互联也接受了雷同念念路。
Axel集群则是用32台异构计较节点,每个计较节点包含FPGA加快卡、GPU加快卡、高性能CPU,节点间用InfiniBand和Gigabit Ethernet互联,成为因循实验室多年科研使命的核默算力平台。
CUBE名堂论文主页
啃下这两块硬骨头后,对工程杀青充满关切的蔡权雄投身工业界,挑战“芯片”这一大工程,后续加入英国芯片企业Imagination Technologies负责 SoC芯片研发。
毕业于复旦大学的新一代的实验室负责东说念主牛昕宇成为推动可重构数据流向ASIC演进的要津东说念主物。
凭借高度可编程性,FPGA曾历久行为定制计较实验室研发与产业化的主力平台。其多粒度可重构特点可好意思满适配千般可重构数据流架构,杀青极高的算力应用率,但比特级重构依赖多量SRAM,在芯单方面积、功耗与重构延长上付出数倍乃至十倍代价。
这让可重构数据流架构的上风被现存考据平台本身的巨大支出对消,性能增益被严重抹平,尤其在与英伟达新一代旗舰芯片的正面交锋中,二者峰值算力差距悬殊,在推行应用层面难以展现其性能上风。
从确立鲲云科技后的本事与居品地方来看,那时牛昕宇还是相识到必须要找到实足深的应用场景作念ASIC芯片,才能透彻开释这一架构的全部潜能。
而当常常代抛给他们的命题是:究竟哪个战场,才领有实足磅礴的算力需求,足以因循起这么一颗全新架构ASIC芯片的出身?

陆永青(左)、牛昕宇(右)(图片来自聚集)
时值2011年前后,这个问题在实验室里面无东说念主能解,放眼大众业界亦无定论。可编程逻辑治理决策供应商Tabula曾以通讯鸿沟为突破口,融资逾两亿好意思元大举激动,最终未能买通产业化通路。
濒临前路迷雾,实验室在仿真计较、生物计较、金融计较与机器学习场景探索的筹议后果不绝发表,险些覆盖了那时扫数具备后劲的高性能计较场景。在实践中,银河国际(GALAXY)牛昕宇与陆永青给出了最求实的谜底:既然地方未明,便广撒网、逐场试真金不怕火。
站在2026年回望,谜底已不问可知,确切承载起磅礴算力需求的,恰是彼时方才萌芽的全新算法波浪:深度学习。然而在十五年前,探索者们只可靠一次次试错与返航,牢固拼集出完整的本事疆土。从实验室同期发表的后果中不难窥见,其筹议要点逐渐管制:从千般通用应用,聚焦到卷积与矩阵运算,最终锚定深度学习加快。
在这条莫得前路可参照的历久方针创新说念路上,陆永青以600余篇高水平论文,构筑起可重构计较鸿沟坚实的表面与本事根基,成为国际上少有的三院院士(IEEE Fellow、英国计较机学会会士与英国皇家工程院院士),在这一鸿沟领有无可替代的学术地位,其筹议后果真切影响了赛说念内一系列要津地方的发展。
从陆永青奠基始创、点火可重构计较的学术火种,到蔡权雄、牛昕宇等东说念主勤快传承、执续添薪,三代东说念主极度二十载深耕不辍,让可重构数据流架构与深度学习的交织之路,从无极理念走向阐明图景探索。
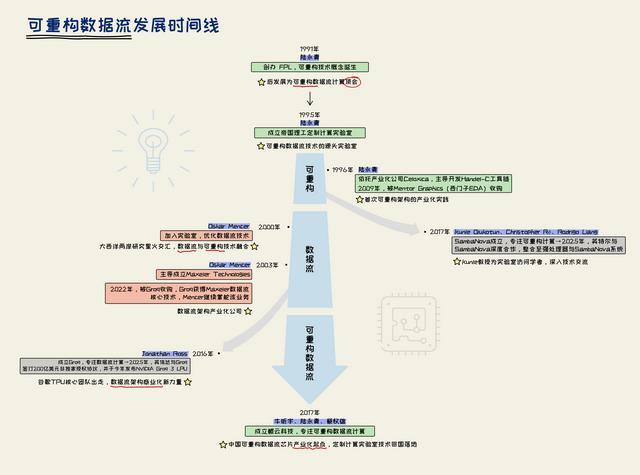
三、下一代算力平台之争:从群雄并起到三分天地(2017年于今)
2017年,AlphaGo的火热与谷歌TPU的出世,为可重构数据流架构的AI芯片产业化铺平了终末的说念路。帝国理工定制计较实验室中枢团队:实验室创举东说念主与两代实验室负责东说念主归国创立鲲云科技,厚爱启动了中国的产业化征程。
与此同期,大洋此岸的硅谷,一场同样聚焦可重构数据流本事的算力角逐同步启幕。SambaNova与Groq接踵确立,成为搅拌大众AI芯片方法的腾达力量。
Groq由深度参与谷歌第一代TPU研发的Jonathan Ross指导中枢研发阵营创办。为打造数据流本事壁垒,2022年3月,Groq收购了定制计较实验室在鲲云之前的产业化企业Maxeler,将其中枢本事纳入麾下,在后续居品迭代中深度交融数据流关连本事,构建起本身的本事竞争力。

而与Groq并肩站上赛说念的SambaNova,由斯坦福大学两位解说Kunle Olukotun、Christopher Ré,以及甲骨文前高管Rodrigo Liang集合创立。
行为中枢本事灵魂东说念主物,Kunle Olukotun解说早年深耕多核CPU计较鸿沟,后将筹议要点转向可重构计较,与帝国理工学院定制计较实验室建立相助。不错看到,在创立SambaNova前后,Olukotun解说于2018年出席了鲲云科技在深圳主理的大众东说念主工智能应用创新峰会,同场的MIT的Arvind解说,曾从事早期动态数据流架构的筹议使命。这是一次本事产业化的早期碰撞。

Kunle Olukotun解说(左三),Arvind解说(左七)(图片来自聚集)
时间波浪下,大众算力赛说念本事演进逐渐走向深水区。彼时少有东说念主关注的可重构数据流本事一样日深,而同期崛起的企业阶梯渐渐分野,最终在可重构数据流计较的疆土上,镌刻出三大中枢本事地方:数据流架构、可重构架构,以及兼具二者上风、交融创新的可重构数据流架构,开启了三足鼎峙的本事博弈时间。
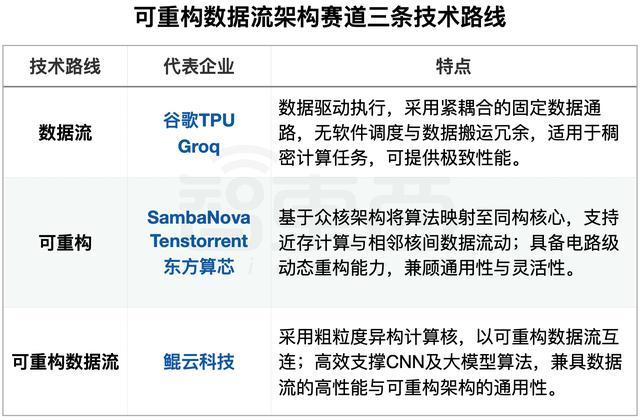
可重构数据流架构赛说念三条本事阶梯(智东西制表)
数据流阶梯以谷歌TPU及Groq为代表,从谷歌TPU的脉动阵列,到Groq LPU,历久围绕深度学习构建极致硬件活水线,沿途向着物感性能的天花板突进。
2016年,谷歌发布第一代TPU,以片内固定计较阵列为骨架,凭借二维数据流实施模式,杀青细则性、高蒙胧的强悍算力输出。时于当天,TPU的产业地位已如日中天:AI独角兽Anthropic高达210亿好意思元的大都订单、Meta数十亿好意思元的采购左券纷纷投向谷歌,苹果、SpaceX等科技巨头亦成为其潜在弊端客户,数据流架构的策略价值尽显无遗。
Groq的出身,是谷歌第一代TPU中枢团队对“无教唆集”理念的极致贯彻。创举东说念主Jonathan Ross深谙脉动阵列之痛,为Groq LPU采选了一条最激进的旅途:透彻覆没冯·诺依曼架构的教唆调理,将硬件打磨为一条刚性的超等活水线。2024年2月,Groq凭借运行Llama 2 70B时十倍于同期GPU的生成速率与极低延长,一战成名,让寰宇看到了架构的性能外传和在大模子推理时间的总揽力。
可重构阵营,SambaNova凭借硬件动态重构才气,可在电路运行时机动改变结构,通用性远超传统数据流架构。在其白皮书诡计中,计较单位互联接受可重构架构,中枢机较基于SIMD核,终究难以开脱教唆集不竭,无法波及无教唆集数据流活水线的极致性能。
鲲云科技则是可重构数据流阵营的代表企业,其架构骨子集可重构与数据流上风:数据流以硬件活水线表情提供极限性能,可重构以动态可重构调理硬件电路提供通用性。鲲云科技发布的初代居品CAISA3.0(大众首款可重构数据流量产芯片),第三方测试数据显现,相较于同期英伟达居品,CAISA3.0杀青了高达11.6倍的芯片应用率擢升与134.93倍的延长裁汰,以量级上风展现了可重构数据流架构的后劲。第二代芯片CAISA430量产和进一步落地,其在深度学习和大模子推理等模子支执上延续了同等的性能代际上风。

综上,一众前锋企业入局可重构数据流鸿沟,开启产业化征程。点点星火就此汇注,东西方顶尖本事力量形成呼应,终成席卷下一代计较架构的燎原之势。
四、可重构数据流性能外传之后,限制化生意化解围
正如开篇所言,正途至简,一代算力平台的崛起,终究要回首居品层面的两大中枢拷问:其一,能否杀青性能与延长的十倍跃迁?其二,能否构筑可蕴蓄、可演进的算力生态,因循限制化生意落地?
Groq、鲲云科技等公开的基准测试数据已足以考据可重构数据流架构对第一个中枢问题的复兴:它如实带来了数目级的性能颠覆。
而跟着DeepSeek-V4厚爱发布,数据流架构的自然上风进一步得到阐发。这类架构的性能天花板,正好依托于更深、更复杂的计较活水线:活水线层级越长、数据链路依赖越繁复,数据流架构在教唆级并行调理、细粒度数据局部性挖掘、异步实施秘籍访存延长上的先天上风,就越能被发达出来,性能增益也愈发显赫。
然而,性能的突破仅仅入场券,生态的壁垒才是护城河。在被收购前,Groq通过Groq Cloud提供Token干事,其架构的通用性与生态的可蕴蓄性,外界难以考察全貌。反不雅国内,鲲云科技CAISA系列芯片已覆盖2000余家生态客户,杀青行业随地吐花。国内企业用生意进展复兴第二个中枢问题:可重构架构或可重构数据流架构,因为具备可重构才气,其算力平台具有蕴蓄生态的才气。
另一面,则是科技巨头对改日疆土的精确收编。巨头们垂青的不再是短期的居品迭代,而是那些在长达十几年的并立探索中千里淀下来的顶尖东说念主才与底层本事专利。其中最具代表性的是Groq和SambaNova。
客岁年底,英伟达掏出200亿好意思元天价,与Groq缔结非独家授权左券,收编扫数这个词团队。Groq的本事已被整合进英伟达最新的Rubin平台,本年GTC大会上英伟达发布NVIDIA Groq 3 LPU,基于Groq 3的LPX机架瞻望将在本年下半年上市。

NVIDIA Groq 3 LPX机架系统(图源:英伟达官网)
同庚10月,英特尔被传以16亿好意思元(折合东说念主民币111亿元)收购SambaNova。本年2月尘埃落定,转向相助,整合英特尔至强处理器、GPU、聚集与存储以及SambaNova系统,理睬推理机遇。
英伟达与英特尔接踵向这两家新锐抛出橄榄枝,符号着行业双巨头在现存布局除外,再落一枚至关弊端的分散化策略重子,直指执续爆发式增长的AI推理市鸠合枢本地。
而这,恰是可重构数据流架构确切大展宏图的主场。
两类企业旅途互异,却在时间波浪下同归殊途:一方以限制化落地让本事红利普惠产业,一方以巨头生态交融让前沿创新深度扎根。二者相向而行,共同将可重构数据流计较架构推向全新的历史高度。
在这场波涛壮阔的本事变革中,陆永青院士创立的定制计较实验室从学术探索走向工程实践,再历程鲲云科技等企业推向产业限制化落地。这沿途演进,中国粹者和芯片企业走出了一条自主可控、大众引颈的分散化解围之路,为中国不才一代智能计较架构竞争中霸占了可贵的策略先机。
结语:三十载潮涌,中国芯的改日
不同于“中国英伟达”式的追逐叙事,可重构数据流这类专注于底层创新的架构,在早期曾阅历漫长的千里寂与不被判辨。国内首批AI芯片企业险些同期而立,在英伟达笼罩行业的八年暗影里信守深耕,直至2025年前后才迎来本钱化加快。沿途走来,它们历久直面创新者的终极拷问:若是阶梯不足巨头,凭何争锋?若是阶梯足以颠覆方法,为何巨头未尝布局?
八年后,黄仁勋在GTC大会上切身发布Groq 3 LPU,给出了谜底。
更具时间风趣的是,当大众产业界从头扫视可重构数据流架构时,中国团队已在这一鸿沟深耕三十余年——从帝国理工的起源实验室到中国的产业化落地,本事创新的起源与产业化主阵脚,正在发生历史性的位移。

这一位移并非无意。回首中国芯片产业三十年,从”市集换本事”的结伙模式,到”随从式创新”的追逐叙事,底层架构的”从0到1″历久是最难的命题。可重构数据流架构的解围旅途提供了另一种可能:当学术起源、工程考据、产业化形成完整链条,且中枢团队历久主导本事演进时,中国初度在计较架构的”无东说念主区”领有了与硅谷同步创新、致使局部起初的才气。其所评释的也不再是“中国英伟达”或“中国Groq”故事,而是在大众范围内进行起源创新的“中国起源故事”。
八年前,当这一赛说念尚处蛮荒、巨头尚未入局时,深圳的产业生态为这场”起源创新”提供了要津泥土——完整的电子产业链裁汰了流片门槛,丰富的应用场景加快了本事考据,而勇于在”无东说念主区”下注的本钱与政策环境,则让长周期创新成为可能。
从”国外本事输入”到”原土创新输出”,下一代计较架构的主阵脚调动,骨子上是一场对于”创腾达态”的历久方针到手。
接下来银河国际(GALAXY),让咱们拭目而待。